
文章目录
展开0.写在前面
搜索是个好东西,但是时空复杂度有局限,所以我们引入了A*,迭代加深,双向宽搜和舞蹈链来解决时空复杂度的问题。
1.舞蹈链
不懂不知道,一懂吓一跳(虽然没有完全懂)。
这个算法/数据结构也太太太太巧妙了吧。
舞蹈链名副其实,确实好看又精巧。
舞蹈链主要解决的是精确覆盖问题。
1.1 精确覆盖问题
1.1.1 问题定义
给定一个由 0-1 组成的矩阵,问是否可以挑出若干行,使得对于这个行的集合,每一列有且仅有一个 1 出现。洛谷传送门

我们可以观察出行 1,4,5 为一个解。可以利用递归回溯得出这个解。
1.1.2 回溯求解
我们先选择第一行(用 蓝色 标记),然后将其中 1 所在的列用 红色 标记,最后将有 红色 的 \color{red}1 的行用 绿色 标记。结果如下:

根据要求,选择 蓝色 行后,所有 绿色 行均与其冲突,不能再选择。所以我们删掉上图中所有带颜色的部分,得到如下矩阵:

于是我们得到了规模更小的新的精确覆盖问题。选择次矩阵的第一行(原矩阵的第二行),再按照上述方法进行标记,结果如下:

再次将所有带颜色的部分删去,得到空矩阵。而此时 蓝色 行有 \color{blue}0 ,说明没有得到解。于是回溯,选择第二行(原矩阵的第四行):

删掉上图中所有带颜色的部分,得到如下矩阵:
选择第一行(原矩阵的第五行),再进行标记,删除,得到空矩阵。而此时 蓝色 行没有 \color{blue}0 ,说明得到一个解。
得到的解为原矩阵的第一行、第四行和第五行。
因此我们可以将该回溯算法总结成如下步骤:
- 选择当前矩阵的一行。
- 标记该行,该行元素为 1 的列,被标记的列中含 1 的行。
- 删除所有标记元素,得到新矩阵。如果新矩阵为空矩阵,跳转到 4. ;否则继续求解,跳转到 1. 。
- 新矩阵为空矩阵。如果删除的行全为 1 ,说明得到一个解,求解结束,跳转到 5. ;否则说明求解失败,跳转到 6. 。
- 求解结束,得到一个解。输出这个解。
- 求解失败,回溯到上一个矩阵,选择下一行,跳转到 1. 。如果没有矩阵可以回溯,说明本题无解,跳转到 7. 。
- 求解结束,本题无解。输出无解信息。
从上述过程来看,我们需要很大的空间来存储缓存和回溯的矩阵。而如何缓存保证数据可以回溯,如何得到对应原矩阵的行的答案等,实现起来较为困难。
1.2 舞蹈链
为了解决精确覆盖问题,高德纳( Donald Ervin Knuth )——经典巨著《计算机程序设计的艺术》的年轻作者,提出了 DLX(Dancing Links X) 算法。实际上,他提出的算法为 X算法 ,而舞蹈链则是实现这个算法的高效的数据结构。在介绍舞蹈链的过程中,我们可以发现其巧妙的结构带来的高效的效率,各元素就像在链上舞蹈一般灵巧。
1.2.1 双向链表
在学习数据结构时,我们曾经接触过链表,其巧妙的插入删除操作让我们对其记忆犹新。
为了解决不同的问题,链表又分为单向链表,双向链表,循环链表等等。
其中双向链表,即每个元素含有两个指针,分别指向前面和后面的元素。
比如我们有三个连续的元素 ABC ,则我们可以用: A.Right=B B.Right=C B.Left=A C.left=B 将其相连。
当我们要删除元素 B 时,我们只需将 B 的左元素的右指针附成 B 的右元素,将 B 的右元素的左指针附成 B 的左元素。即 A.Right=C C.Left=A 。
值得注意的是,此时 B 这个元素的实体还在,只是其不在链中而已。也就是说,此时仍有 B.Right=C B.Left=A 。
当我们还想将 B 插回原来的位置时,只需要 A.Right=B C.Left=B 即可。
再观察上述删除和插入操作,类比上文中的缓存和回溯操作,我们发现其恰好对应,可以灵活运用。而更巧妙的是,它不再需要额外的空间去存储缓存的数据,而是可以直接进行删除和操作,这使得空间复杂度大大降低了。而时间上,插入一个结点和回溯一个矩阵相比也更快了。
另外,我们将双向链表的首尾相连,则得到了 双向循环链表 ,这在实际应用中是很广泛的。
1.2.2 十字交叉双向循环链表
看看这高大上的名字吧。
我们分析一下这个名字, 双向循环链表我们已经介绍过了,那这个十字交叉是什么东西?
我们是将若干条双向循环链表十字交叉得到一个类似于矩阵的数据结构。
我们先来分析两条双向循环链表十字交叉是个什么概念。

这就是一个十字交叉双向循环链表,其中元素 B 不仅在横向的链中,也在纵向的链中。两条双向循环链十字交叉,交点为元素 B 。
对于交点元素,它的指针便有四个。我们记成 B.Left=A B.Right=C B.up=D B.down=E 。
1.2.3 舞蹈链
把舞蹈链单独写个小标题只是因为它是重点,并不代表它跟 十字交叉双向循环链表 不同。恰恰相反,舞蹈链本质就是一个 十字交叉双向循环链表 。
对于上面的样例(怕大家记不住我们把它拿下来):
我们可以构造出如下图的舞蹈链:

不用惊慌,我们一步一步分析这个数据结构。
对于上图(下文称作 DLX )中的每个结点,都含有六个元素。可以视为每个结点是 DLX 中的一个元素,而每个结点本身又是一个包含六个更细小元素的结构体。这六个元素分别为 left,right,up,down,row,col 。前四个我们上文说过,元素 row 指向该结构体所在的行标,元素 col 指向该结构体所在的列对应的列元素(见下文)。
而对于 DLX ,我们将其中的元素分为三种。
第一种为 DLX 中的数字,如上图的 1-17 ,它们表示原矩阵中的 1 。这也是 DLX 中最为重要的结点。因为精确覆盖问题一般给出的都是稀疏图,所以这些结点的个数不会很多。
第二种为 DLX 中的列元素,如上图的 C1-C7 ,它们是辅助元素,作用是方便 DLX 运作。它们的 row 为 0 , col 为本身, left,right 为列元素或 head 元素。
第三种,或者说第三个为 DLX 中的 head 元素,它也是辅助元素,且只有一个,作用也是方便 DLX 运作。它没有 up,down,row,col 元素。换句话说,它只有 left,right 元素有用。
下面我们来具体谈一谈这样一个 DLX 究竟是如何工作的。
我们首先给出 DLX 的步骤:
- 判断
head.right==head。如果等于,说明求出解,输出答案并返回true;否则,继续。 - 取列元素
c=head.right。 - 遍历列元素所在列链,选择一行。
- 删除与该行链元素冲突的行列,得到一个新的 DLX 。
- 如果新的 DLX 中仍有列元素且列链为空,则返回
false;否则跳转步骤 1. 。 - 如果选择该行后未求得解,则回溯到当前状态,选择下一行,跳转步骤 5. 。如果所有行都遍历过仍未求得解,说明之前有行选择错误或无解,返回
false。 - 如果最终函数返回值为
false,则输出No Solution!。
下面根据上述步骤进行对样例的模拟:
head.right!=head,取c=head.right=1,遍历列元素所在列链(得到元素 4,10 )。
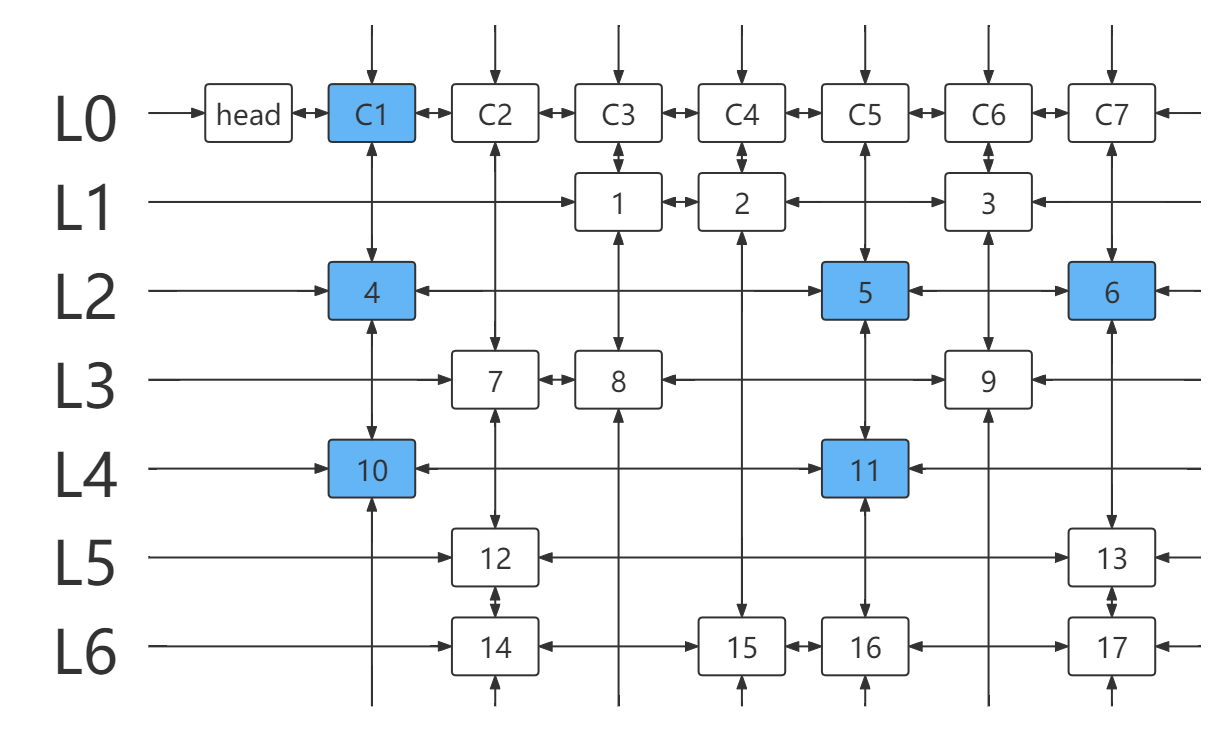
- 选择元素 4 所在行 L2 ,并处理与该行链元素冲突的行列。

- 得到新的 DLX 。
head.right!=head。
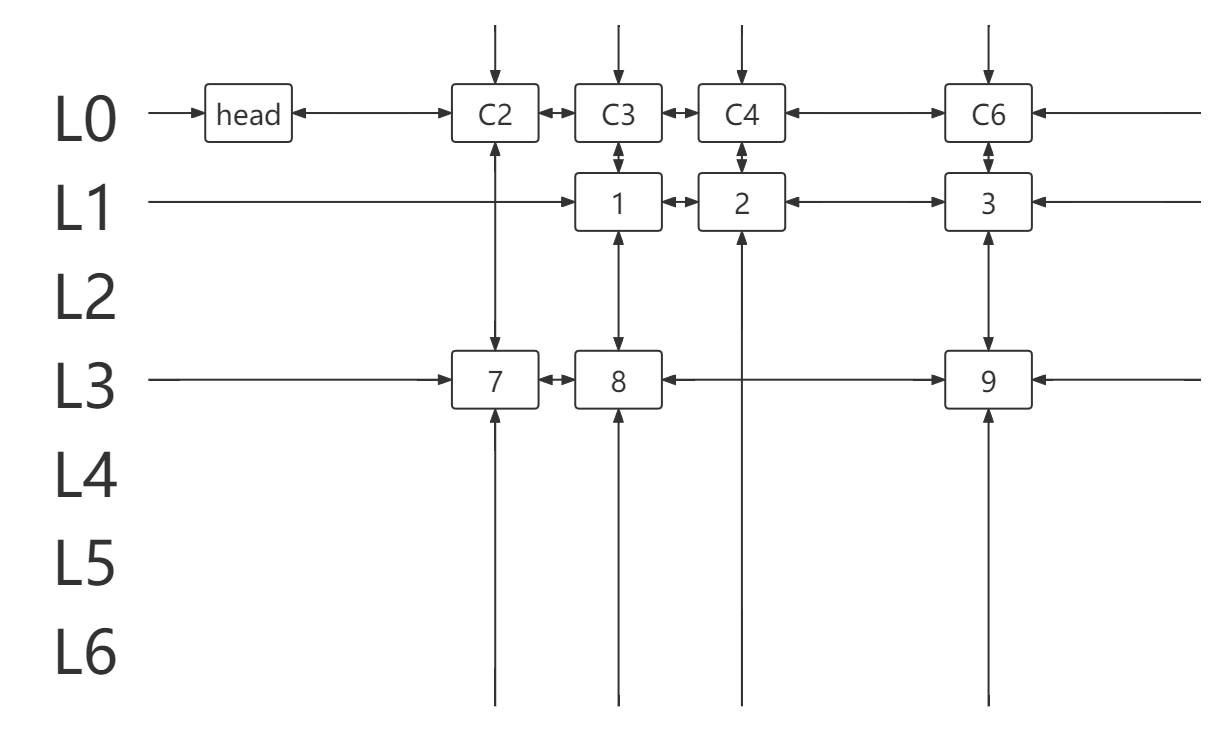
4.取 c=head.right=2 ,遍历列元素所在列链(得到元素 7 )。
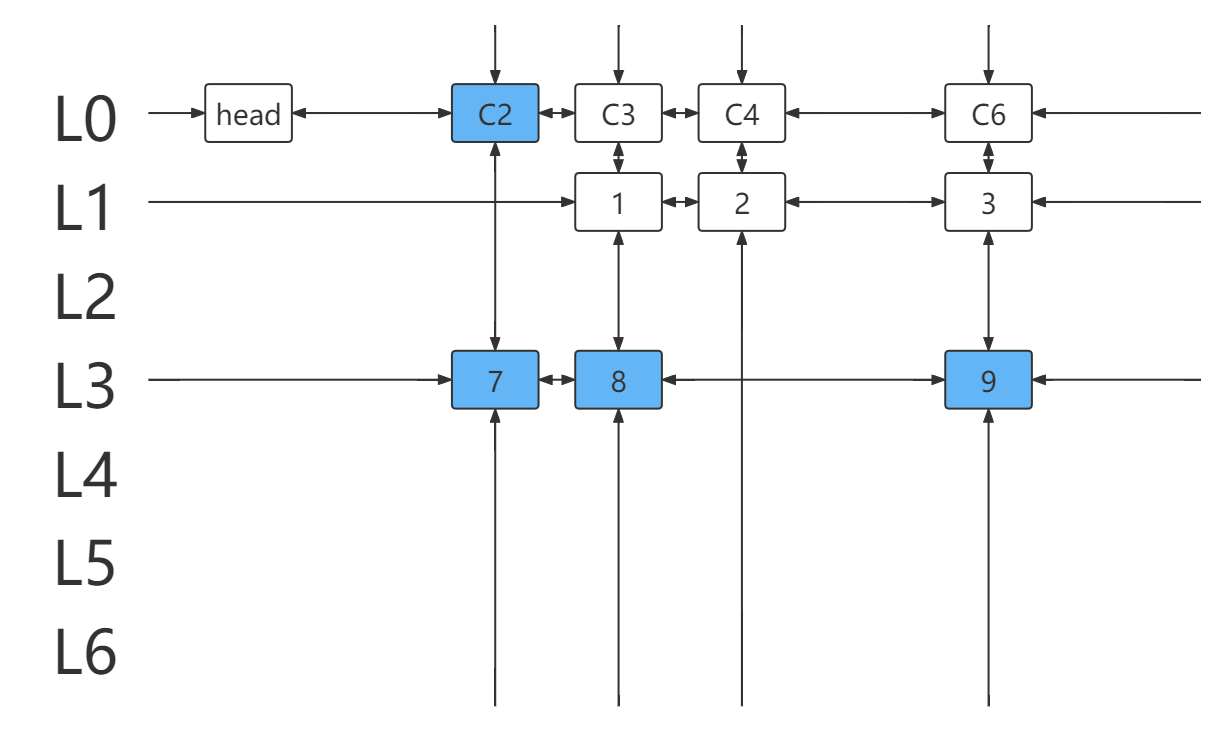
- 选择元素 7 所在行 L3 ,并处理与该行链元素冲突的行列。
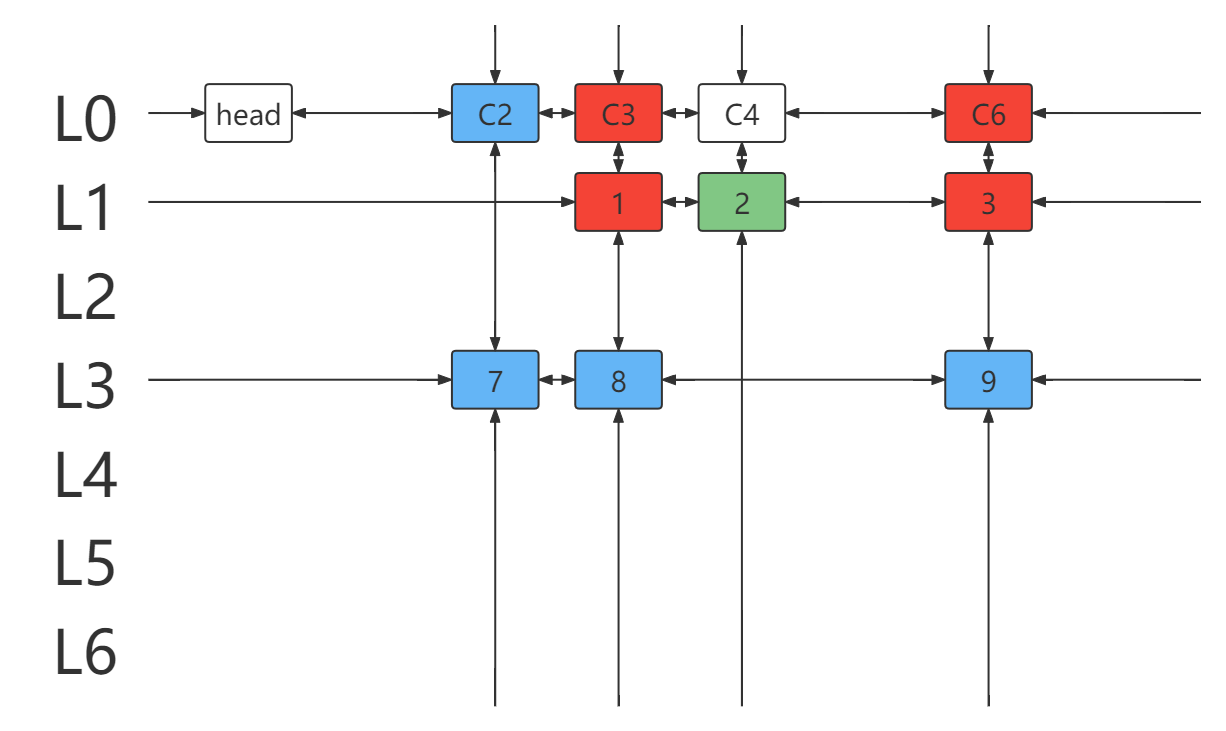
- 得到新的 DLX ,仍有列元素且列链为空,返回
false。(说明没有满足要求的行能覆盖该列)
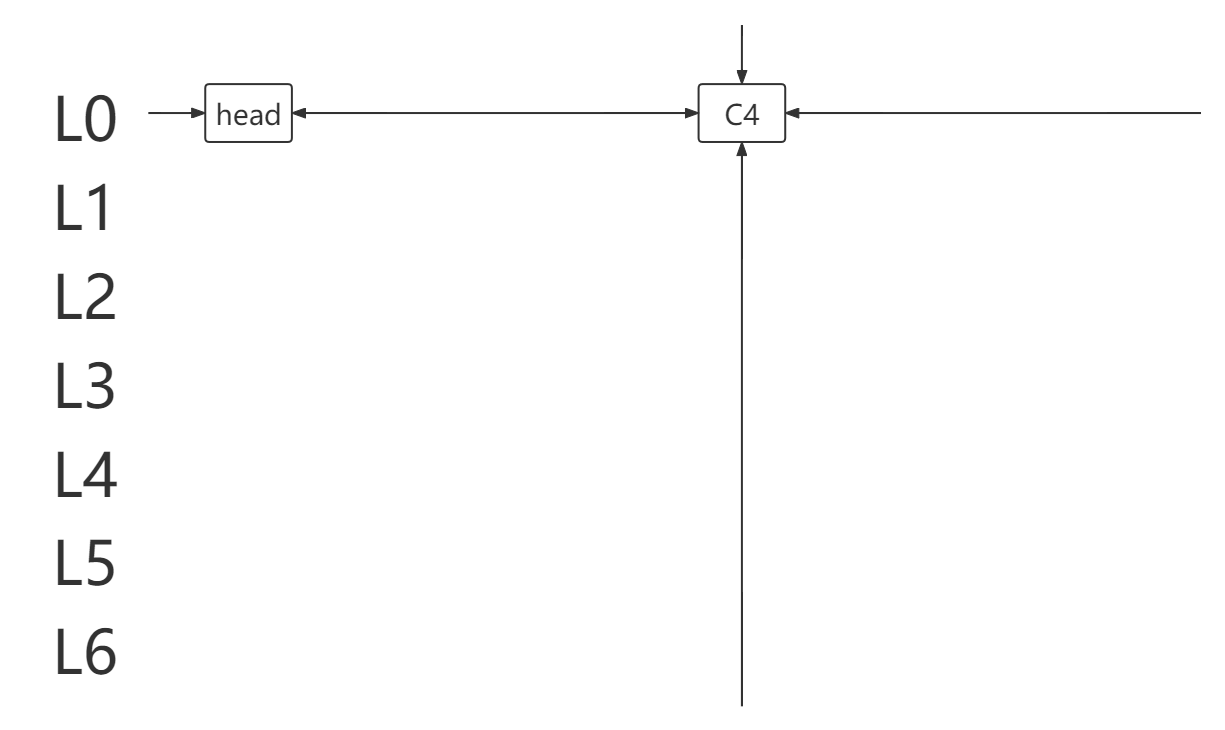
- 上图返回模拟步骤 4. ,此时所有行都遍历过仍未求得解,说明之前有行选择错误或无解,返回
false。

- 上图返回模拟步骤 1. ,列元素所在列链含有元素 4,10 , 4 选择过,无解。
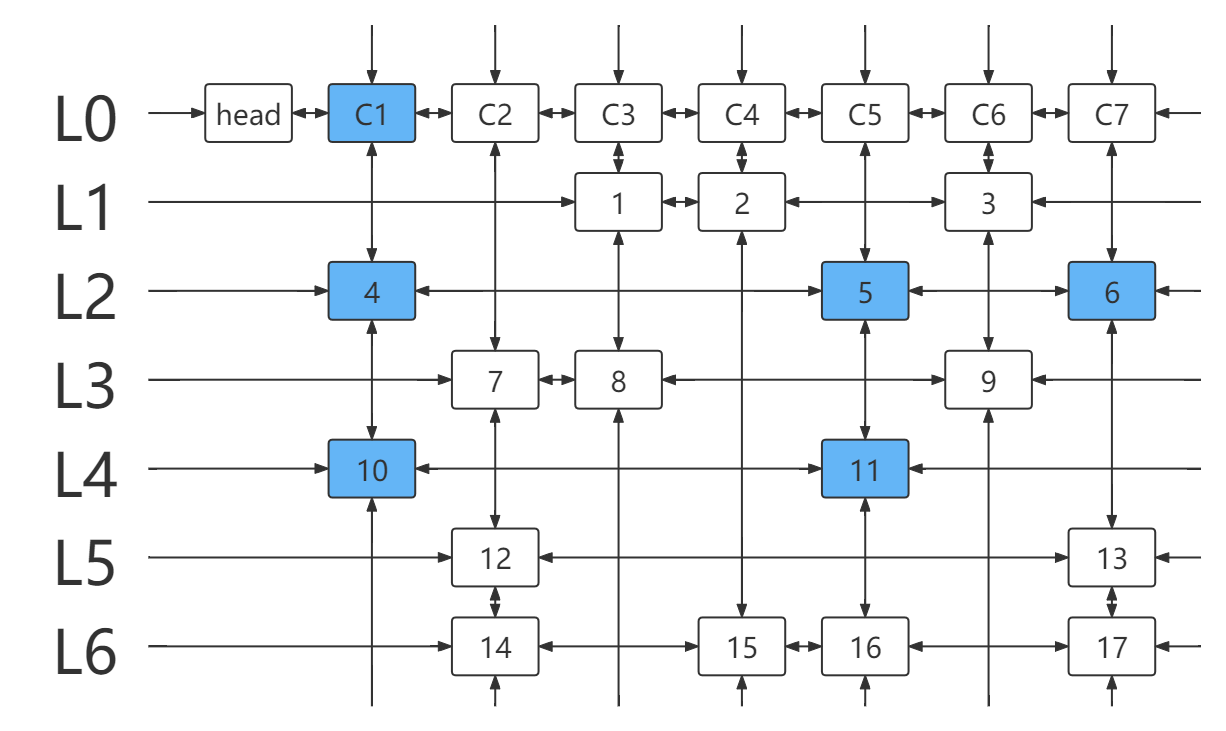
- 选择元素 10 所在行 L4 ,并处理与该行链元素冲突的行列。
- 得到新的 DLX 。
head.right!=head。

- 取
c=head.right=2,遍历列元素所在列链(得到元素 7,12 )。
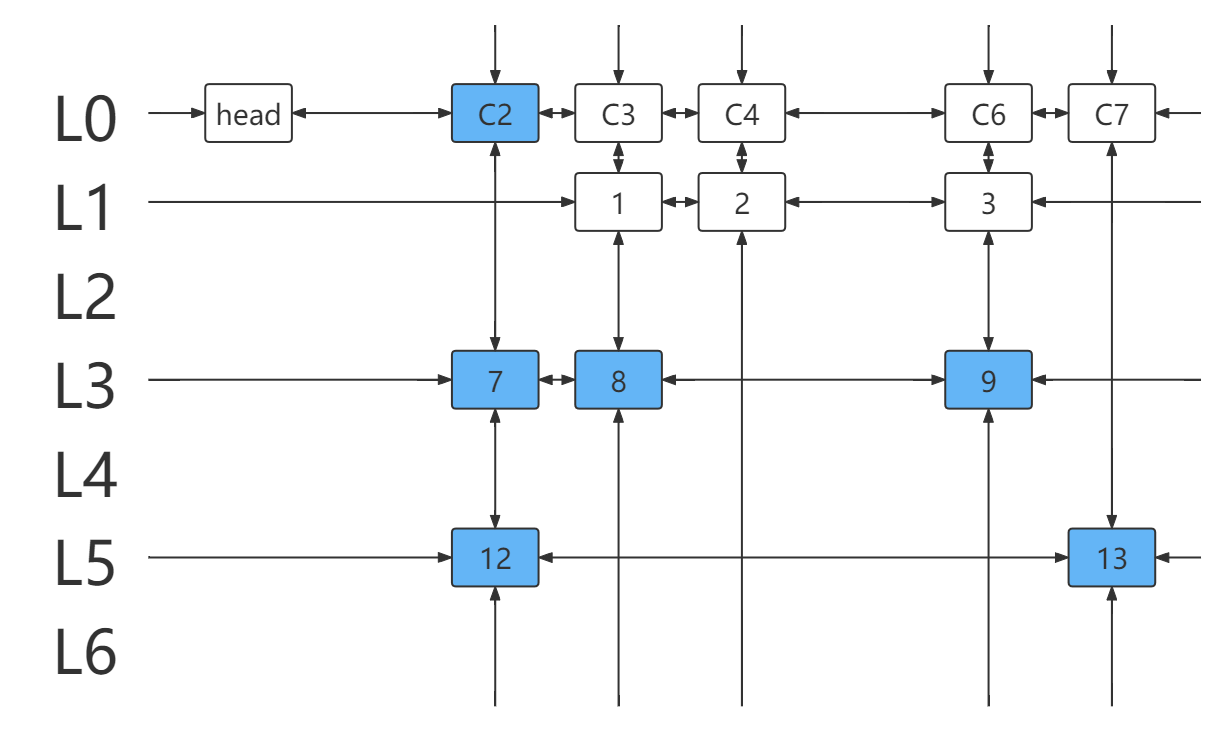
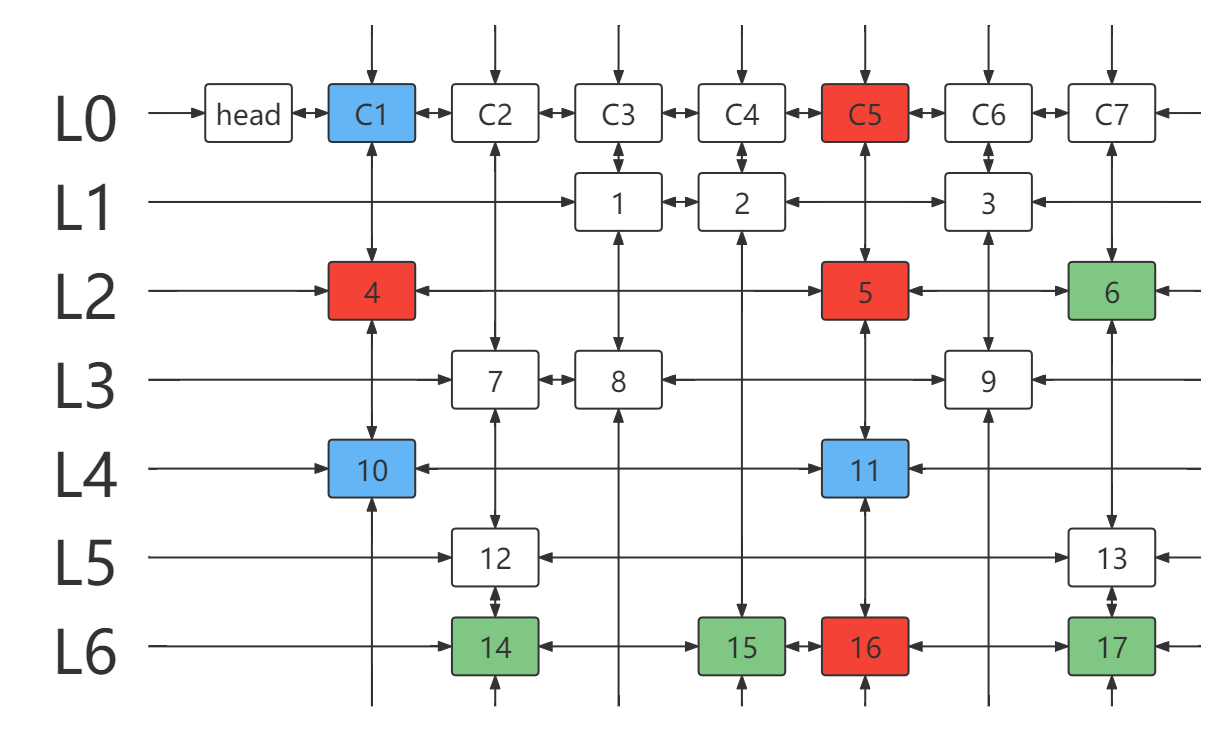
- 选择元素 7 所在行 L3 ,并处理与该行链元素冲突的行列。
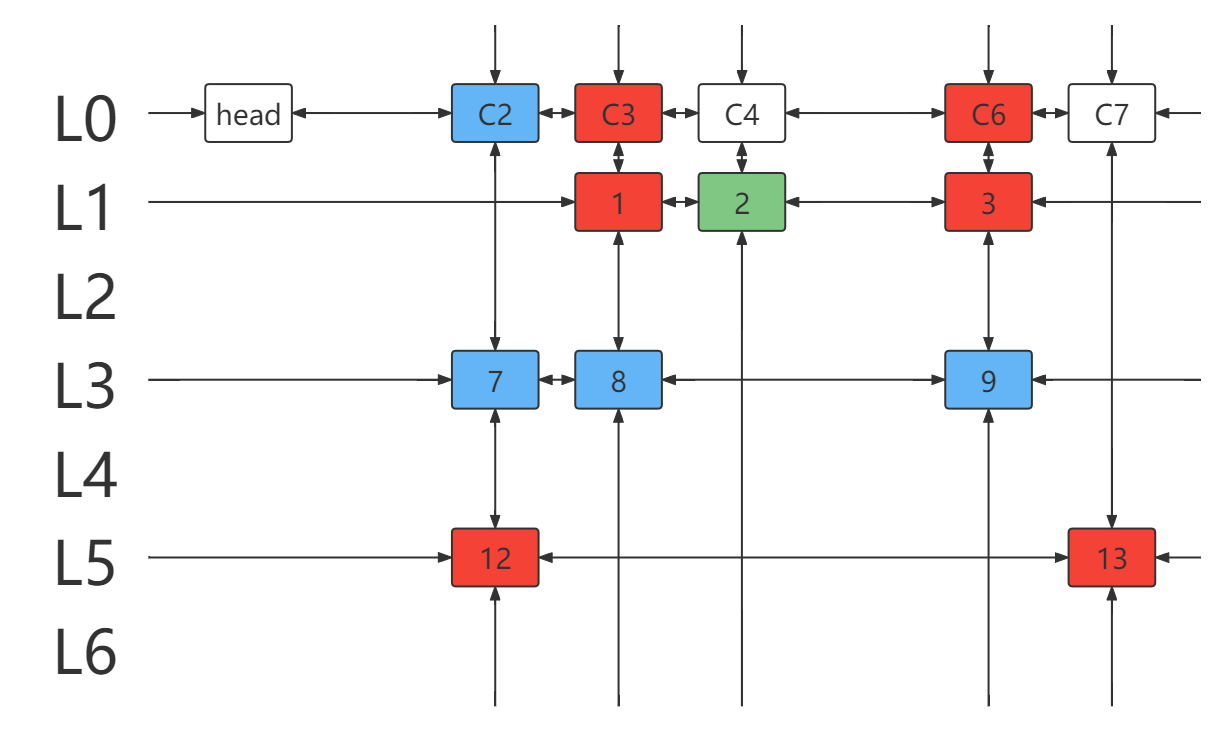
- 得到新的 DLX ,仍有列元素且列链为空,返回
false。(说明没有满足要求的行能覆盖该列)
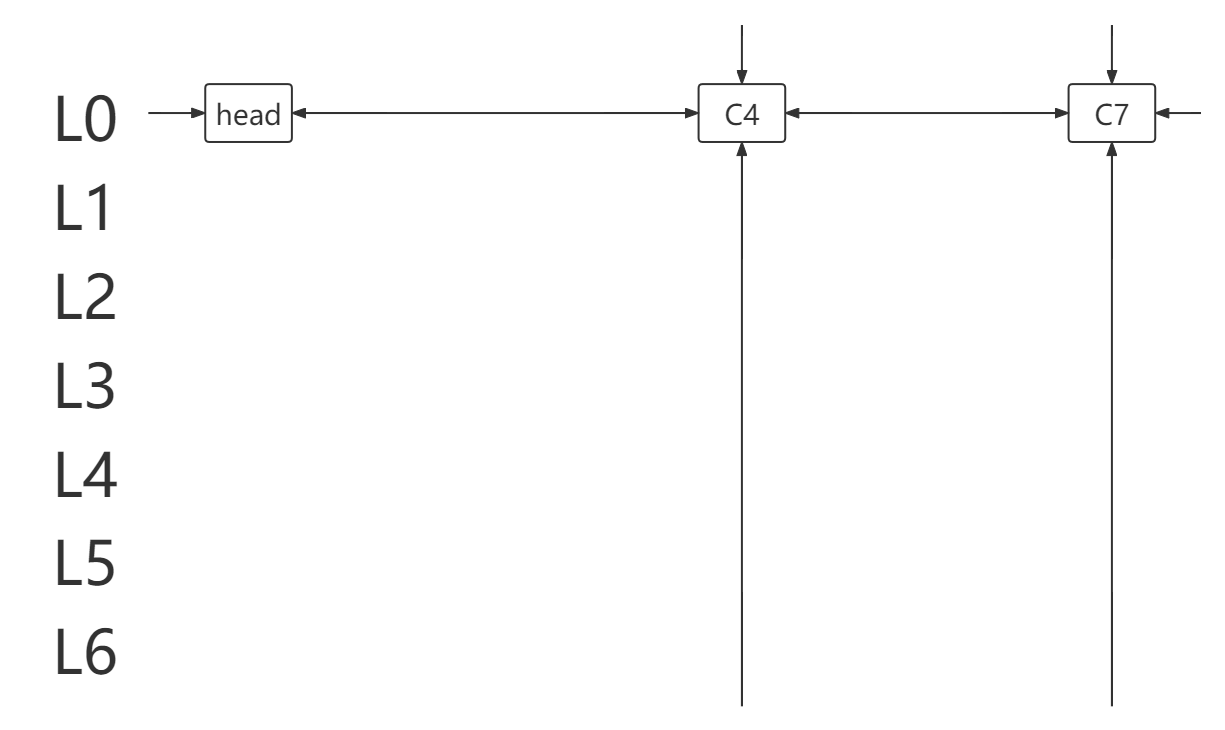
- 上图返回模拟步骤 11. ,列元素所在列链含有元素 7,12 , 7 选择过,无解。

- 选择元素 12 所在行 L5 ,并处理与该行链元素冲突的行列。
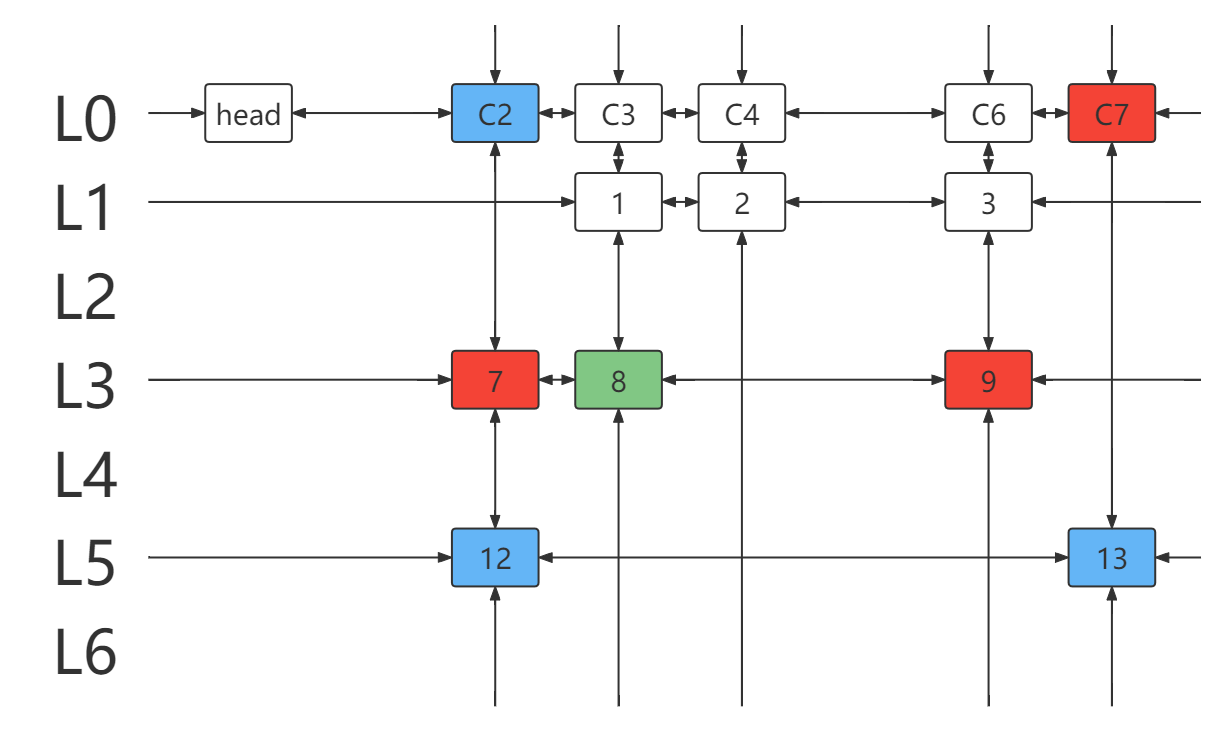
- 得到新的 DLX 。
head.right!=head。
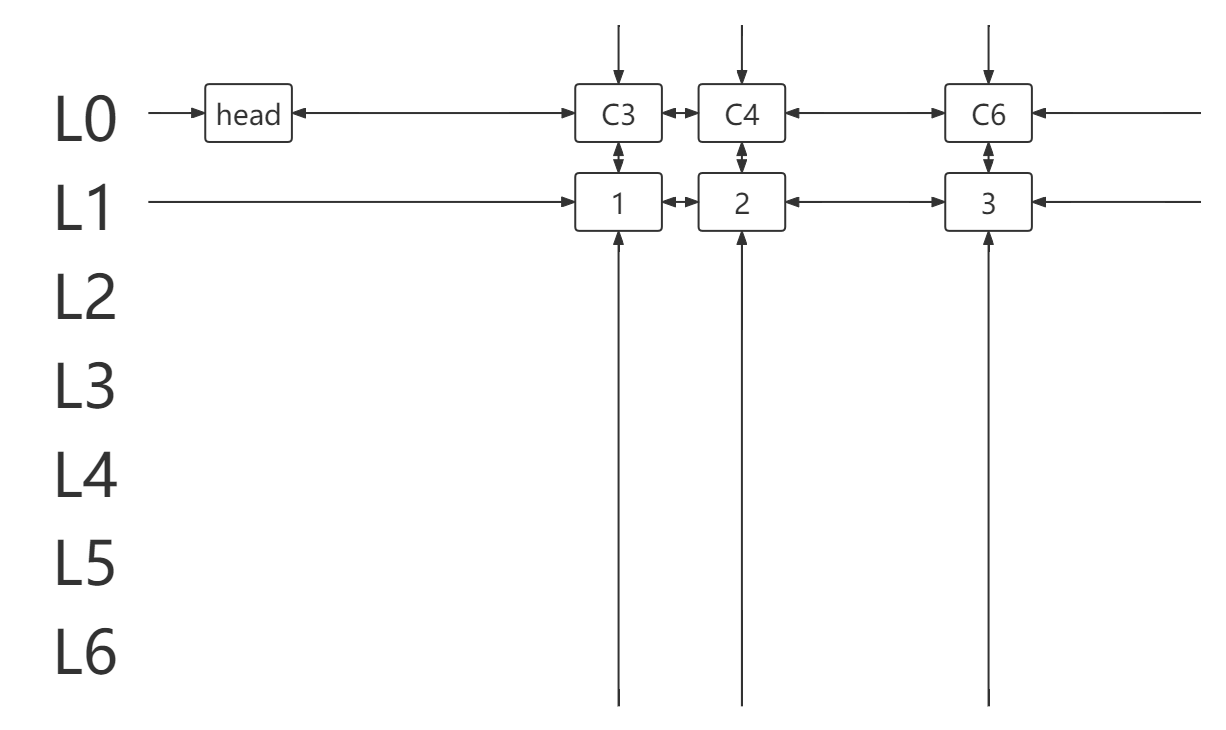
- 取
c=head.right=3,遍历列元素所在列链(得到元素 1 )。

- 选择元素 1 所在行 L1 ,并处理与该行链元素冲突的行列。

head.right==head,得出解。

- 输出解: L4,L5,L1 。
1.3 代码讲解
1.3.0 定义
|
1 2 3 4 5 6 7 8 9 10 11 |
struct DLXnode { int Row,Col; int Left,Right,Up,Down; }; int cnt=0; DLXnode node[6000];//DLX中的所有元素,包括head元素和列元素 int row[510];//每行第一个元素 int ans[510];//记录答案 int lcnt[510];//每列元素个数 |
结构体部分与上文对应。
其中 row 是为了建 DLX 时更方便,一个辅助数组。
lcnt 是用来提速的(),具体用法在 dance() 中会体现。只需记住它记录的是每列的元素个数即可。
1.3.1 初始化
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
void init() { for(int i=0;i<=m;i++) { node[i].Left=i-1; node[i].Right=i+1; node[i].Up=i; node[i].Down=i; lcnt[i]=0; } node[0].Left=m; node[m].Right=0; cnt=m; } |
初始化的是 head 元素和列元素。将它们的上下左右指针指好,列指针和行指针可以不用。
1.3.2 添加 ‘1’ 结点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
void addnode(int r,int c) { //修改该结点所在行链 node[++cnt].Row=r; node[cnt].Col=c; node[cnt].Up=node[c].Up; node[cnt].Down=c; node[node[cnt].Up].Down=cnt; node[c].Up=cnt; //修改该结点所在列链 if(!row[r])//该结点是其所在行的第一个元素 { node[cnt].Left=cnt; node[cnt].Right=cnt; row[r]=cnt;; } else//该结点不是其所在行的第一个元素 { node[cnt].Left=node[row[r]].Left; node[cnt].Right=row[r]; node[node[cnt].Left].Right=cnt; node[node[cnt].Right].Left=cnt; } lcnt[c]++;//对应列元素个数++ } |
1.3.3 删除列元素所在列链及其中元素所对应行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
void remove(int c) { for(int i=node[c].Down;i!=c;i=node[i].Down)//枚举列链中元素 for(int j=node[i].Right;j!=i;j=node[j].Right)//枚举列链中元素所对应行链中元素并删除 { node[node[j].Down].Up=node[j].Up; node[node[j].Up].Down=node[j].Down; lcnt[node[j].Col]--; } //删除列链(仅需删除列元素即可删除整个列链) node[node[c].Left].Right=node[c].Right; node[node[c].Right].Left=node[c].Left; } |
1.3.4 恢复列元素所在列链及其中元素所对应行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
void resume(int c) { //恢复列链(仅需恢复列元素即可恢复整个列链) node[node[c].Left].Right=c; node[node[c].Right].Left=c; for(int i=node[c].Down;i!=c;i=node[i].Down)//枚举列链中元素 for(int j=node[i].Right;j!=i;j=node[j].Right)//枚举列链中元素所对应行链中元素并恢复 { node[node[j].Down].Up=j; node[node[j].Up].Down=j; lcnt[node[j].Col]++; } } |
1.3.5 Let’s Dance ! ! !
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
bool dance(int dep)//dep表示答案的个数(搜索的层数) { if(node[0].Right==0)//如果head.right==head,说明有解,输出答案 { for(int i=1;i<dep-1;i++) printf("%d ",ans[i]); printf("%d\n",ans[dep-1]); return true; } int C=node[0].Right;//取列元素 c=head.right 。 for(int i=node[0].Right;i;i=node[i].Right)//提速(见文字) { if(lcnt[i]<lcnt[C]) C=i; } remove(C);//删除列链 for(int i=node[C].Down;i!=C;i=node[i].Down)//枚举选择行 { ans[dep]=node[i].Row; for(int j=node[i].Right;j!=i;j=node[j].Right)//删除选择行链元素所在列链 remove(node[j].Col); if(dance(dep+1))return true; for(int j=node[i].Right;j!=i;j=node[j].Right)//恢复选择行链元素所在列链 resume(node[j].Col); } resume(C);//恢复列链 return false; } |
上述提速的枚举,在正常的舞蹈链中可以不加。它的作用仅仅是提速。
但是在洛谷的舞蹈链中,如果不加这个枚举,会 TLE 四个点,就算吸了氧也会 TLE 两个点。
因此我们加了这个提速的枚举。原理是减少搜索树的分叉数。
首先我们知道,取所有列中任意一列进行操作对于结果没有影响,因此我们选择列中元素最少的列,这可以使得搜索树的分叉数大大减少(尤其是当搜索层数较高时)。
另外,代码中 remove(C) 和 resume(C) 也可以写在循环中,也就是 remove(node[i].Col) 和 resume(node[j].Col) 。但其实删除的都是同一行,所以写在外面可以减少一点点复杂度。不理解的话就背板子(当然也可以问),但最好还是理解理解。
1.3.6 主函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
int main() { scanf("%d%d",&n,&m); init(); for(int i=1;i<=n;i++) for(int j=1;j<=m;j++) { scanf("%d",&x); if(x==1)addnode(i,j); } if(!dance(1))printf("No Solution!\n"); return 0; } |
没什么好讲的,如果上面所有内容都理解了,这个主函数肯定能看懂。
1.4 数独
数独是很经典的问题了,解数独有很多种方法。